
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 경사하강법
- 아다부스트
- C4.5
- 부스팅
- 체인지업후기
- 선형모형
- MultipleLinearRegression
- Adaboost
- gradientdescent
- 군집화기법
- 캘리포니아주택가격예측
- 중선형회귀
- cost complexity pruning
- 실제데이터활용
- 의사결정나무
- pre pruning
- LinearRegression
- 부스팅기법
- post pruning
- KNearestNeighbors
- 최소제곱법
- 정보이득
- 선형회귀
- LeastSquare
- 사전 가지치기
- 사후 가지치기
- 회귀분석
- AdaBoostClassifier
- AdaBoostRegressor
- boosting
- Today
- Total
데이터 분석을 향한 발자취 남기기
[Boosting] AdaBoost Classifier 본문
Boosting의 대표적인 알고리즘인 AdaBoost 알고리즘에 대해서 알아보고자 한다. AdaBoost는 분류와 회귀 문제에 모두 사용할 수 있는 앙상블 모델로 오늘은 분류 문제를 다뤄보고자 한다.
1. AdaBoost Classifier Algorithm
2. Simple example
1. AdaBoost Classifier Algorithm
AdaBoost는 Boosting 알고리즘이므로 오분류된 샘플들을 찾아 다음 분류기가 이를 집중적으로 학습할 수 있도록 하는 것이다. 약한 학습기 (weak learner)들을 적절하게 결합하여 강한 학습기 (strong learner)를 구성하며, 훈련 오류율(error rate)를 이용해 샘플의 가중치를 설정한다.
- AdaBoost Classifier Algorithm
이진 분류 AdaBoost Classifier에 대한 알고리즘은 다음과 같다.

* 초기 가중치를 설정한 경우 기존 데이터에 모델을 훈련시킨다. 그후, 업데이트된 가중치를 이용하여 그다음 훈련에 사용할 데이터를 샘플링하고 모델을 훈련시킨다.
- AdaBoost 특징
Bagging의 대표적인 알고리즘인 Random Forest는 분류기들이 모두 동일한 영향력을 지니지만, AdaBoost는 상대적으로 더 영향력($\alpha_{t}$)이 큰 분류기들이 존재하며, 이에 따라 분류를 진행한다.
2. Simple example
AdaBoost Classifier를 간단한 예제를 통해 이해해보고자 한다. 주어진 데이터는 2개의 설명변수 $X_{1}, X_{2}$와 반응변수 $y = {-1, 1}$가 주어진 이진분류 문제이다.
- $t = 1$
총 5개의 경우로 구성되어 있으므로 초기 가중치 $w_{1}(i) = \frac{1}{5} = 0.2, i = 1, \cdots , 5$로 설정한다.

초기 가중치를 설정했으므로, 기존 데이터를 이용해 stump tree를 생성한다. tree는 분류 시, leaf node 내 가장 많은 class로 분류하므로 조건에 성립하면 class 1로 성립하지 않으면 –1로 예측한다.
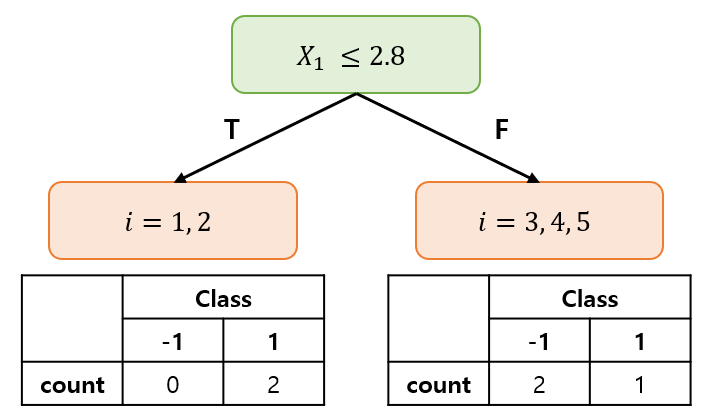
훈련 오류율 $\varepsilon_{1}$을 계산했을 때, 0.2로 0.5보다 작으므로 루프를 계속 진행한다.

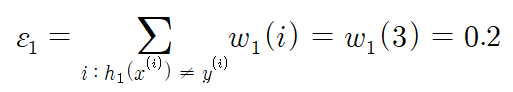
오류율을 이용해 $\alpha_{1}$을 계산한다. 그후, 이를 이용해 오분류된 샘플의 가중치는 증가시키고 정분류된 샘플의 가중치는 감소시킨다.
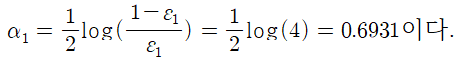

이제, 가중치에 $Z_{1} = 0.1+0.1+0.1+0.1+0.4 = 0.8$을 나누어 정규화한다. 그 결과, 오분류된 샘플의 가중치는 이전보다 증가하고, 정분류된 샘플의 가중치는 이전보다 감소했음을 볼 수 있다.

- $t = 2$
가중치 $w_{2}(i)$를 이용해 훈련 데이터를 샘플링한다.
↓

샘플링된 데이터를 이용해 stump tree $h_{2}$를 학습시키고 훈련 오류율 $\varepsilon_{2}$와 $\alpha_{2}$를 계산한다. 이때, 훈련 오류율은 기존 데이터를 이용해 계산한다.



오분류된 가중치는 증가시키고 정분류된 가중치는 감소시킨다.

이후, 가중치 $w_{3}(i)$는 $Z_{2} = 0.2887+0.0722+0.0722+0.2165+0.2165 = 0.8661$ 을 이용해 정규화하여 계산한다.

이를 1번 더 반복해 총 3개의 트리를 생성하였다고 가정한다.
- $t = 3$

가중치 $w_{3}(i)$를 이용해 새로운 샘플링 데이터를 생성한다. 이를 이용해 stump tree $h_{3}$를 생성하고 훈련 오류율 $\varepsilon_{3}$과 $\alpha_{3}$를 계산한다.


- Final Predict
위에서 생성한 AdaBoost Classifier를 이용해, 새로운 데이터를 예측하고자 한다.

최종 예측을 위해, 앞서 구한 $alpha_{t}$와 분류기 $h_{t}$를 결합한다.

이를 이용해, $g(x)$와 $sgn(g(x))$를 계산하여, 최종 예측값을 계산한다. 이때, $sgn(x)$는 $x$가 0을 초과하면 1, 0 미만이면 -1을 내보내는 함수이다.

AdaBoost Classifier를 통해 실제 class와 일치하는 예측결과를 생성하였다.
오늘은 Bagging과 Boosting에 대해서 간략하게 살펴보고 AdaBoost Classifier에 대한 알고리즘을 공부하였다. 또한, 간단한 예제를 이용해 이를 적용해보았다. 다음 포스트에서는 AdaBoost Classifier를 실제 데이터에 적용하고 결과를 해석해보고자 한다.
'손으로 직접 해보는 모델정리 > 앙상블 모델' 카테고리의 다른 글
| [Boosting] Gradient Boosting Regressor (0) | 2023.04.28 |
|---|---|
| [Boosting] AdaBoost Classifier with Citrus (0) | 2023.04.12 |
| [Boosting] AdaBoost Regressor (0) | 2023.03.28 |
| 앙상블 학습 방법 (0) | 2023.03.24 |



